If your mental image of “AI” starts and ends with a large language model running in a massive data center, you’re not alone.
ChatGPT, Claude, and similar tools have become the public face of artificial intelligence — but they represent only one narrow slice of a much broader toolbox. In practice, many of the most useful applications of AI don’t involve conversation at all, don’t require the internet, and don’t run on powerful servers.
They run on microcontrollers — including devices as small and inexpensive as an ESP32.

This post is about that other side of AI: small, pre-trained models running locally to solve narrow, well-defined problems — reliably, cheaply, and with very little power.
AI vs LLMs: A Useful Distinction
It helps to separate the technology into two camps.
Large Language Models (LLMs)
- Are general-purpose
- Require enormous datasets and training compute
- Typically run in the cloud
- Excel at language, reasoning, and synthesis
Embedded AI (often called TinyML)
- Are task-specific
- Are trained once, offline
- Run locally on constrained hardware
- Excel at classification, detection, and pattern recognition
Both are “AI.” They just solve very different problems.
An LLM is optimized for breadth and flexibility.
An embedded model is optimized for repeatability, efficiency, and constraints.

What “AI on an ESP32” Actually Means
Let’s clear up a common misconception: the ESP32 is not training models.
The heavy lifting happens on your PC — once. The ESP32 simply applies what it has already learned.
You invest effort in data collection and training up front. After that, the device repeats the same decision process consistently, millions of times.
The workflow looks like this:
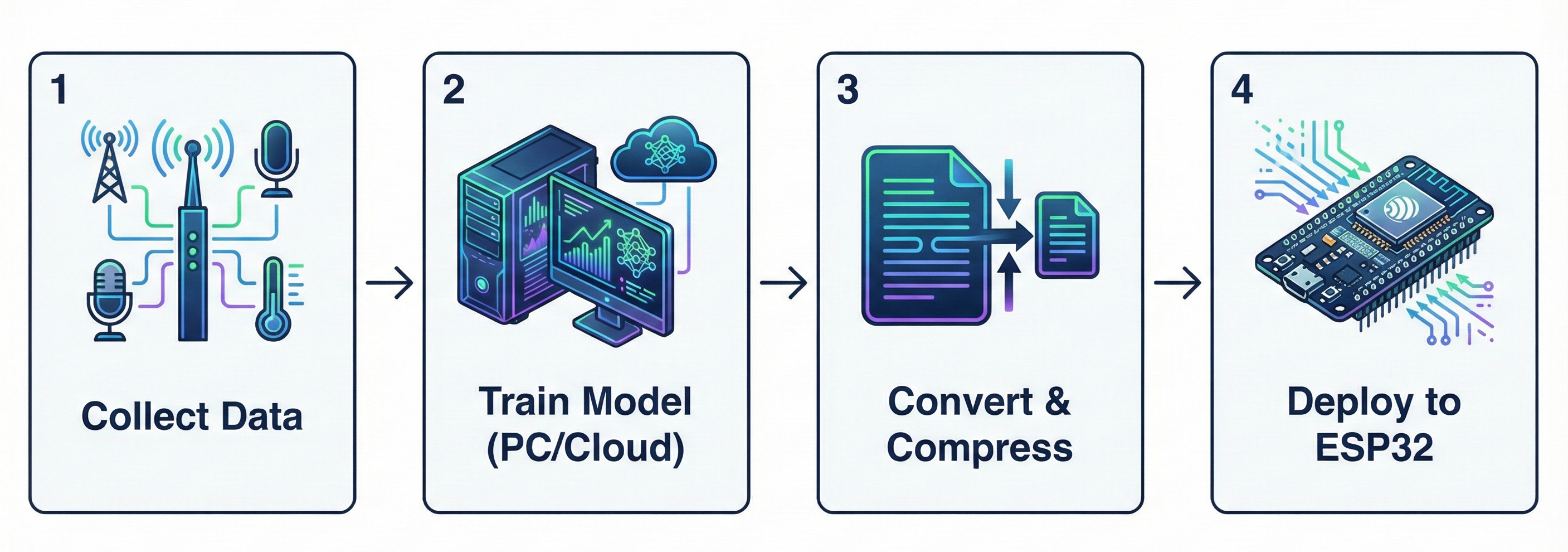
- Collect data (sensor readings, audio snippets, images, etc.)
- Train a model on a PC or cloud machine to recognize patterns in that data
- Convert and compress the model (typically via quantization)
- Deploy it to the ESP32 as a fixed inference engine
Once deployed, the ESP32 is doing one thing only: running inference. It takes live input and classifies it based on what it learned offline.
Practical ESP32 AI Use Cases
Here are some realistic tasks where a pre-trained model on an ESP32 makes sense.
1. Audio Monitoring (Without the Privacy Risks)
Instead of streaming audio to the cloud to be processed — slow, power-hungry, and invasive — you train a small audio classifier to recognize specific acoustic signatures.
- The task: recognizing a wake word, a specific clap pattern, or the sound of a machine bearing beginning to fail
- The benefit: logic triggers only when confidence exceeds a threshold
No speech recognition. No language processing. No audio ever leaves the device.

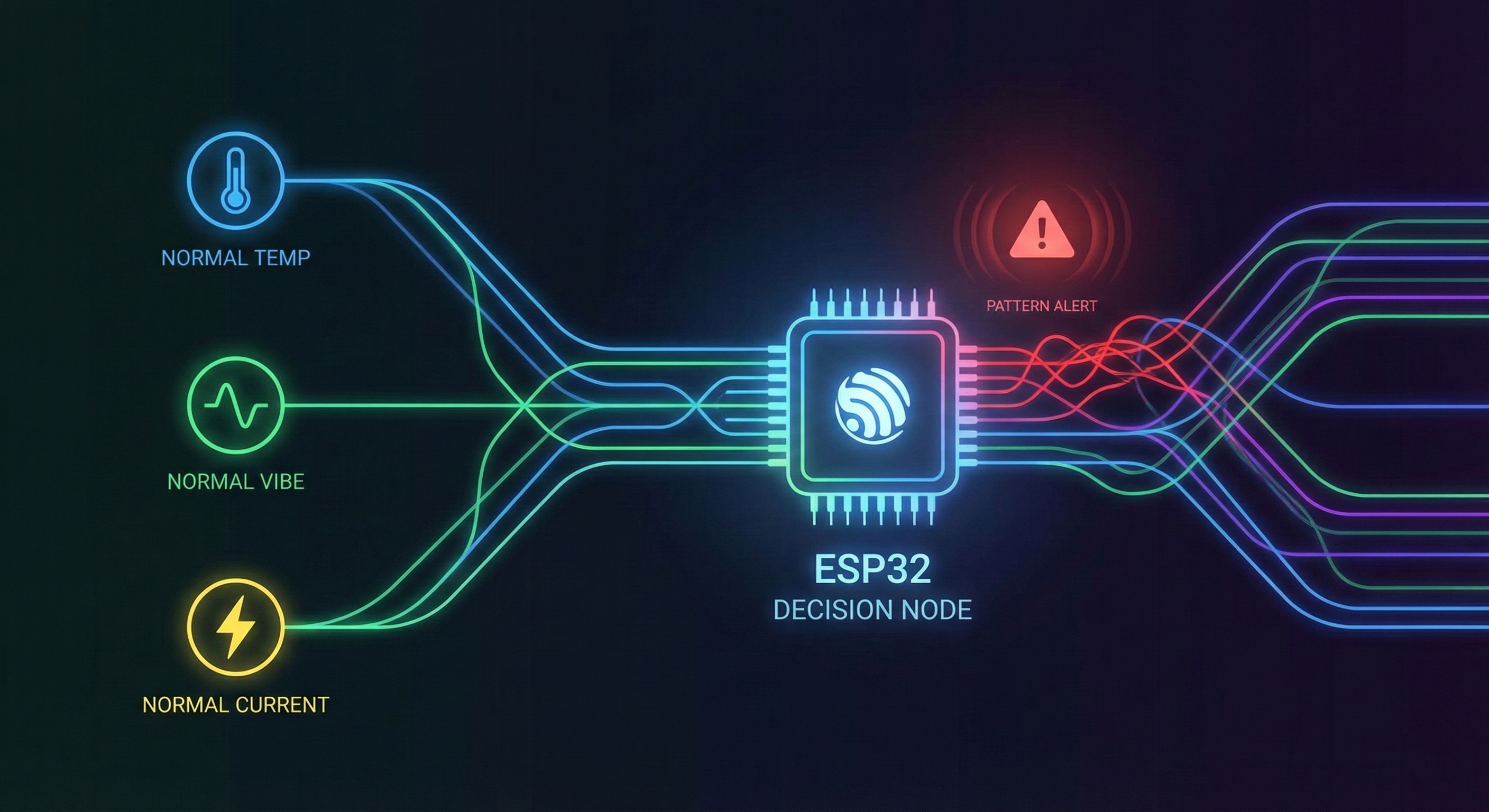
2. Sensor Fusion (Spotting the Invisible Fault)
Traditional embedded logic says: “If temperature > X, do Y.” Embedded AI says: “This specific combination of temperature, vibration, and current draw looks wrong.”
This is sensor fusion, and it’s one of the most valuable industrial applications of embedded intelligence.
A slightly elevated temperature might be normal. Elevated temperature plus a specific vibration frequency and a rise in current draw? That’s a predictive maintenance alert waiting to happen.
3. Visual Inspection (Under Controlled Conditions)
With an ESP32-CAM, you aren’t doing facial recognition or complex object sorting. You’re doing fast, low-resolution checks.
- The process: downscale images aggressively (grayscale or binary) and run tiny CNNs
- The task: “Is the connector present?” “Is the label missing?” “Is the part roughly in the right position?”
These models thrive in consistent environments. Fixed camera position and controlled lighting (like inside an enclosure or on a production line) are what make small vision models reliable.
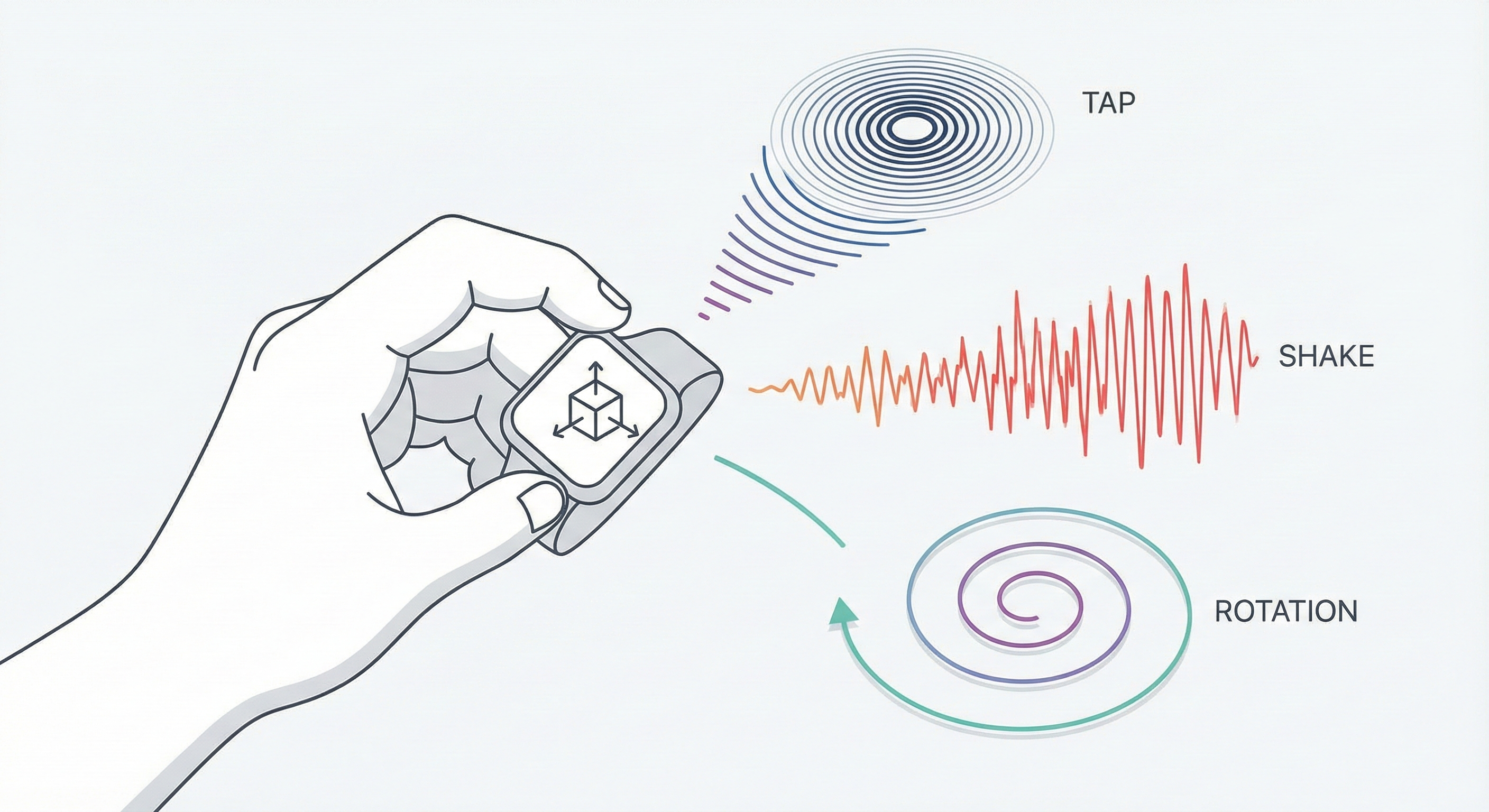
4. Motion and Gesture Classification
Using IMUs (accelerometers and gyroscopes), you can analyze short windows of motion data and classify behavior.
- The task: differentiating a tap from a shake, detecting orientation changes, or identifying handling states
- The benefit: far more robust than raw thresholds, allowing you to distinguish intentional input from accidental noise
A Simple Mental Model
If LLMs are about understanding meaning, embedded AI is about recognizing patterns.
The ESP32 doesn’t “know” anything. It answers very specific questions:
- Does this look like A or B?
- Is this normal or abnormal?
- Is this state closer to on or off?
That’s often exactly what you want.
Why Engineers Should Care
For product developers, this opens up an important middle ground.
Embedded intelligence is smarter than hard-coded rules, simpler than cloud-based AI, cheaper than high-end processors, and easier to validate, test, and certify.
Why heat the entire room when you only need to warm the person? Why deploy a massive AI system when a tiny, focused model does the job better?
Where Kotatsu Fits In
This is the kind of problem space we enjoy working in:
- Defining the right task for AI (often smaller than expected)
- Selecting sensors and hardware
- Designing the data-collection process
- Integrating embedded intelligence into a product — cleanly and practically
AI doesn’t need to be magical. It just needs to be useful.
If you’re exploring embedded intelligence in a prototype or early product — and want to do it without unnecessary complexity — that’s a conversation we’re happy to have.
Related reading: The Invisible Spaghetti: Why Wire Routing is the Last Thing You Model and the First Thing to Fail